
TL;DR
原文: Zanzibar: Google’s Consistent, Global Authorization System
Introduction
Zanzibar 是 google 开发和部署的一个全球授权系统,用于评估全球用户对 google 数百个应用的访问权限(包括:Calendar, Cloud, Drive, Maps, Photos, YouTube等)。目前已经存储了上万亿条 ACL(access control list),每秒钟处理来自数十亿用户的数百万个请求,并且在过去的三年里做到了将 95% 分位的请求响应时延控制在 10ms以内,系统的可用性大于99.999%。本文主要是描述了 Zanzibar 系统在工程实现上遇到的挑战和解决方案。
Zanzibar 系统的几个设计目标:
- 正确性:保证用户设置的访问控制策略能被正确实现(譬如不能将用户的私人图片开放给别人访问)
- 灵活性:可以同时满足用户和应用对访问策略的多种个性化需求
- 低时延:因为授权请求位于访问请求的干路上,因此授权请求的响应速度决定了用户的体验
- 高可用:当授权系统不可用时,用户的访问请求默认被拒绝,从而导致所有系统不可访问,因此高可用性再怎么强调都不为过
- 大规模:系统需要存储数十亿用户的数据,并且还要全球部署来保证用户就近访问
Model, Language, and API
Relation Tuples
在 Zanzibar 里,一条 ACL(又被称为 relation tuple) 其实就是描述了一个 object-user 或者 object-object 之间的关系。Zanzibar 设计了一个创新性的描述语言来描述一个 ACL(对应下图中的<tuple>) :

通过下图的几个例子就可以弄清楚这个描述语言的原理,注意上图中的<userset>是可以进行递归解析的,由此可以描述出一个非常复杂的权限关系,如下图划红线的语句: group:eng#member

为了应对复杂的权限描述,Zanzibar 还支持权限之间的集合操作(并集,交集等)
New enemy problem
考虑两个场景:
场景一:
 正常情况下Bob 是看不到 Charile往文件夹里添加的新文件,但如果步骤 1 和步骤 2 在写入数据库时乱序了,就可能出现这种情况:步骤 2 已经落库了,但步骤 1 还没落库,此时发生了一次数据库查询,就会导致 Bob 还能看到 Charile 添加的新文件,因为 Bob 的权限还没移除。但是只要保证两个步骤落库时一定是严格按照时间的,那么在步骤 1 落库之后的任何时间点查询数据库,Bob 都看不到新增加的文件
正常情况下Bob 是看不到 Charile往文件夹里添加的新文件,但如果步骤 1 和步骤 2 在写入数据库时乱序了,就可能出现这种情况:步骤 2 已经落库了,但步骤 1 还没落库,此时发生了一次数据库查询,就会导致 Bob 还能看到 Charile 添加的新文件,因为 Bob 的权限还没移除。但是只要保证两个步骤落库时一定是严格按照时间的,那么在步骤 1 落库之后的任何时间点查询数据库,Bob 都看不到新增加的文件场景二:
 假如两个步骤严格按照时间落库了,Bob 还能看到文件里新增内容的唯一可能就是在查询权限的时候,没有查询到最新的这两个 ACL 内容(注意:有两种场景会导致这个情况:
假如两个步骤严格按照时间落库了,Bob 还能看到文件里新增内容的唯一可能就是在查询权限的时候,没有查询到最新的这两个 ACL 内容(注意:有两种场景会导致这个情况:
- 场景一:这两个 ACL 落库时写入到主库之后还没同步到从库,此时查询从库就会看不到这两个 ACL
- 场景二:ACL 已经落库了,但是在查询的时候限定错了时间范围,导致没有查询到最新的这两个 ACL
该论文并没有明确给 “new enemy problem” 下具体的定义,只是说如果没有严格遵从 ACL 更新的因果顺序或者采用了过时的 ACL 就会导致出现该问题。Zanzibar 解决 “new enemy problem” 的方法如下(其实就是做两件事:1.保证 ACL 严格按照因果关系落库;2.客户端在查询数据库时提供一个具体的时间戳,保证数据库能查询到该时间戳之前落库的 ACL):
- external consistency(外部一致性):
外部一致性就是事务在数据库内的执行序列不能违背外部观察到的顺序。举例来说,事务在一个节点写入一条数据,完成后立即另启一个事务在另一个节点读取,能成功读到刚刚写入的数据吗?如果没读到,可以理解成在数据库层面,后一个事务先于前一个事务运行了,这样就违背了外部所观察到的顺序[1]。Zanzibar 依赖于google 的 Spanner 分布式数据库来保证外部一致性,而 Spanner 则通过 TrueTime 来提供该特性,关于该原理可以参考论文:[译]Spanner,TrueTime和CAP定理

- snapshot reads with bounded staleness(受限过期的可读快照):由于外部一致性保证了 ACL 在落库时是严格遵守因果关系的,因此要读取时间戳为 T 的 ACL 快照时就一定能读取到所有在 T 之前落库的 ACL 内容。
Zanzibar 在响应客户端的权限查询请求时需要指定一个数据库的快照时间戳来查询 ACL,如果是单体数据库,那么每次查询 ACL 的时候只需要使用最新一个事务的时间戳即可。但是在分布式数据库的场景下,由于数据库节点之间存在数据不一致的问题,如果每次查询都使用最新事务的时间戳,就会导致数据库节点之间为了同步数据而进行大量的跨区域通信,从而导致高时延。Zanzibar 为了避免这种情况,设计了以下协议:
- 当客户端要更新 ACL 时,Zanzibar 会触发一次 content-change ACL check,然后为这次变更生成一个 token(命名为 zookie),该 token 内置编码了该事务插入数据库时的时间戳,并且在数据库里,ACL 的变更内容会和该 token 一起写入数据库(注:为什么 zookie 不直接使用明文时间戳?这是为了阻止客户端在查询 ACL 的时候传入任意的时间戳,而不是真正有效的时间戳)
- 客户端在后续调用 ACL check API 时需要传入该 token,以此来保证数据库一定能查询到该 token 对应的时间戳数据;如果没有传入该 token,Zanzibar 就会根据本数据库节点已有的数据来查询,换句话说,假如当前的数据库节点还没来得及同步最新的更新数据,并且客户端也没有传入 token,就会导致 Zanzibar 返回错误的结果。
总的来说:外部一致性能保证 ACL 落库时是严格按照用户的变更顺序进行的,因为任何的乱序都会导致权限系统返回错误的结果。而 zookie 则是为了提高系统响应速度而设计的,在分布式数据库里,不同数据中心之间的数据库并不是强一致的,当某个查询请求到达任意一个数据中心的数据库时,最快的响应方法就是基于该数据库已有的数据直接查询返回,而不是等待整个数据库进行一次全球同步后再查询返回。换个角度来理解,zookie 的用途就是为了检查某个数据库是否能够直接查询返回,如果 zookie 编码的数据在该数据库上不存在,此时在进行一次数据库同步即可,相反,如果不存在再进行同步。
Namespace Configuration
在 Zanzibar 里,namespace 是对权限的抽象描述,如下所示:
- 所有的 owner 都是 editor,所有的 editor 都是 viewer,对应到中文语意里就是该文档的所有者都拥有编辑权限,拥有编辑权限的用户同时都拥有阅读权限。
- 对该文档所在文件夹具有阅读权限的用户同时具有阅读本文档的权限
- 其中,union 表示各种权限之间的并集关系

另外,namepsace 里其实还存储了一些重要参数,譬如本 namespace 对应的 ACL 要保存多久,以便垃圾回收进程定时清空过期的 ACL 数据。
API
Zanzibar 的所有 API 都使用 gRPC 封装后暴露出来,主要包括了 Read,Write,Check,Watch,Expand 这五个 API,具体的作用看论文,这里不赘述
Architecture and Implementation
Zanzibar 的系统架构如下所示:
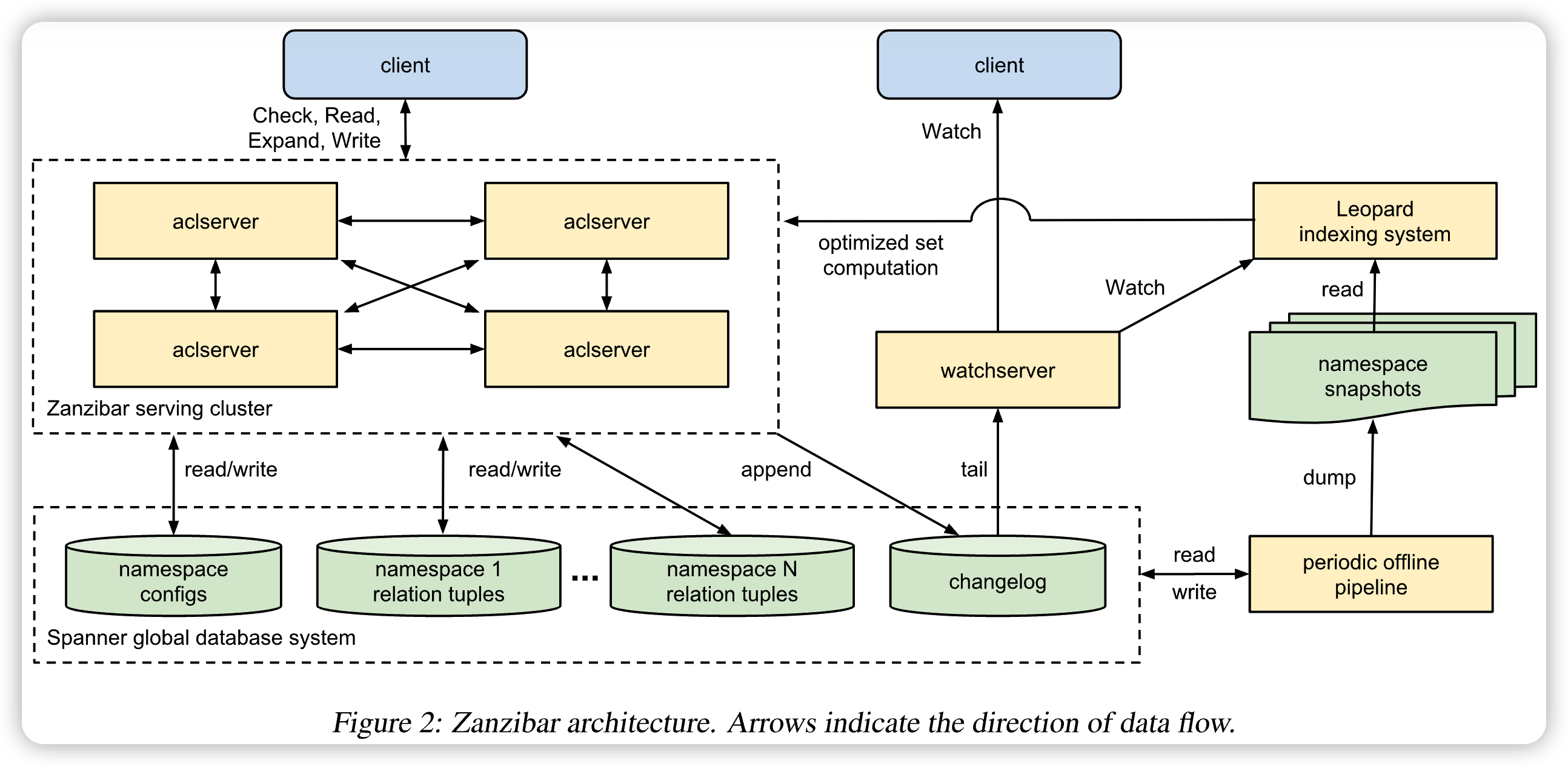
- aclserver:接收请求(Check, Read, Expand, Write),计算结果后返回,注意:aclserver 在处理请求的时候可能会并发出大量的请求到其他服务器上
- watchserver:专门用于响应 Watch 的 API 请求,实时跟踪 changelog 以便更新缓存里的数据,避免每次处理请求时都要加载数据库。但是不同节点在读取 changlog 的时候可能因为网络时延导致数据不一致,此时就需要有一个监控进程来跟踪所有节点都生效的数据并将该数据广播给全局节点
- periodic offline pipeline:定期备份数据和回收一些过期的 ACL
- Leopard:一个索引系统,专门给 watchserver 发送 Watch 请求来实时获取某些 namespace 的变更事件并生成索引,用于加速搜索一些涉及到权限集合的操作(并集,交集等)
Storage
- Namespace Config Storage(namespace 配置):用两个表来保存,一个保存具体的 namespace 定义,另一个表保存 namespace 的变更日志(使用时间戳来索引)。保存变更日志是为了持续监控该表,当发现数据更新时就刷新内存
- Relation Tuple Storage(权限元组):namespace 定义了抽象的权限描述,relation tuple就是定义了具体的权限描述。举例来说,namespace 定义了 “所有的 owner 都是 editor,所有的 editor 都是 viewer”,那么 relation tuple 就是定义“用户 Alice 是文档的 owner,用户 Bob 是文档的 viewer”。所以 relation tuple 是用于指定具体的 user-object 或者 object-object 之间的关系,在数据库中,每条 tuple 对应一行记录,并由多列主键索引(shard ID, object ID, relation, user, commit timestamp).其中 shard ID 的生成规则由 namespace 来指定,一般与 ObjectID 相同。
- Changelog(变更日志):当 relation tuple 更新了内容后就会同步在 changelog 中写入新的记录(二者的操作在同一个事务中),专门用于响应Leopard 发出的 Watch 请求
- Replication(副本):每一个数据中心都保存了全部 ACL 数据的副本
Serving
Evaluation Timestamp
前面已经提到过客户端如果没有传入 token(编码的时间戳) 时,Zanzibar 为了性能考虑,会尽量避免数据库之间进行跨区域通信来同步数据。此时 Zanzibar 就会猜测一个时间戳来查询数据库,然后根据查询的结果和复杂的统计方式来动态调整猜测的时间戳(统计方式可以查看原文,此处不再描述)
Config Consistency
如果某个 namespace 的配置文件发生了变更,由于网络延迟的原因会导致不同的 aclserver 加载到了不同版本(此处的版本其实指的是namespace 落库时的时间戳)的 namespace 内容,此时就会导致服务出错。Zanzibar 会使用一个监控任务来收集所有 aclserver 都可以使用的 namespace 版本号,当请求到达 acvlserver 后,aclserver 会从这些版本号中选择一个使用。这样做的好处是即使 aclserver 不能读取数据库,也能保证整个集群可以继续运行。
Check Evaluation
Zanzibar 会将一个权限检查的请求转化为一个布尔表达式求值问题,譬如要检查用户 U 是否对某个 object 拥有 relation 关系可以转化为表达式:

其中,U’ 表示的是深层嵌套后需要递归查询的 user,举个例子,某个文件放在一个文件夹下面,拥有该文件夹编辑权限的用户也可以编辑本文件。数据库里有一条明确的 ACL 说 Bob 拥有该文件的编辑权限,此时要查询 Alice 是否也拥有该文件的编辑权限。那么在数据库里是查询不到一条具体 ACL 说 Alice 拥有文件的编辑权限,此时就需要递归查询拥有文件夹编辑权限的全部用户里是否有 Alice 这个用户。如果该文件夹又嵌套在另一个文件夹里,就会引发很深层次的递归查询。Zanzibar 会并发查询这些表达式,如果某个表达式得到了结果,就可以取消还没查询完成的其他结果,从而加快查询的速度。同时,Zanzibar 也会将这些请求整合成一个批量查询来减轻后端数据库的压力。
Leopard Indexing System
Zanzibar 为了加速查询上面所述的权限深度嵌套问题,引入了 Leopard 索引系统,该索引系统的原理可以查看原文
Handling Hot Spots
热点数据的处理对 Zanzibar 来说非常重要,因为 2/8 原则的存在,20%的对象占据了 80%的查询请求。Zanzibar 的一个 server 集群会组成一个分布式缓存,然后使用一致性哈希算法[2]来实现请求的负载均衡。
- 当权限查询请求到达后,server 会根据要查询的 ObjectID 计算出一个 forwarding key,然后根据该 forwarding key 和一致性哈希算法将请求路由到不同的 server 上
- 每个缓存的条目都有对应的时间戳(毫秒级)
- 在每个 server 上维持一个 lock table 来跟踪热点对象,当多个请求要访问同一个 cache key 时,实际上只有一个请求得到执行,其他的请求只需要等待返回即可。
- 如果探测到了热点对象(统计读取该对象的请求数量),就会直接加载该对象相关的所有 tuple 到内存中,避免查询数据库
- 如果有多个请求在访问 lock table 里的同一个对象,那么已经在执行的请求就不会被取消,即使该请求可能因为关联请求已经得到响应而无需继续执行。这样做的原因是为了将请求的结果缓存起来,以供被 lock table 阻塞的请求得到结果,而无需再重新发起一次新的调用
Performance Isolation
论文里的这部分准确来说是资源隔离,目的是为了在分布式系统中进行故障容错
- 在 server 上计算每个 RCP 请求所消耗的 CPU 时钟,当server 的 CPU 使用率/内存超过阈值之后会对该 server 的请求进行限流
- 限制同一个客户端或请求对 Spanner 数据库并发查询的最大数量,避免 Spanner 被某个请求或客户端完全独占
Tail Latency Mitigation
为了加速处理慢任务,Zanzibar 使用请求对冲[3]的方法,原理如下:
- 实时评估一个请求的响应时间,如果超过阈值就会被认为是一个慢任务,此时就会发出第二个一模一样的请求,当某一个请求得到响应后就取消掉另一个请求
- 每一个 server 会根据所有请求的响应时间来动态计算慢任务的响应时间阈值,以便控制请求对冲导致的无效流量比例
- 请求对冲时,不同的请求一定是针对存放了副本的其他server 集群,因为在同一个 server 集群里反复发起请求只会导致执行更多的慢任务,使得性能更差
Experience
这部分的内容用几个指标(存储,QPS,响应时延,可用性等)描述了 Zanzibar 系统在过去 5 年里的运行情况,更详细的信息请阅读原文
参考
[1] 数据库的外部一致性
[2] 一致性哈希(Consistent hashing)算法
[3] [笔记] The Tail at Scale